🎯 Introduction : Le défi de l'inspection industrielle multi-vues
🎯 Introduction: The Challenge of Multi-View Industrial Inspection
🎯 はじめに:マルチビュー産業検査の課題
Imaginez que vous devez inspecter des bouteilles en verre sur une chaîne de production. Une seule caméra ne suffit pas : selon l'angle de vue, certains défauts sont invisibles à cause de la transparence du matériau, des reflets lumineux, ou simplement parce qu'ils sont cachés. La solution ? Utiliser plusieurs caméras placées à différents angles pour observer le même objet.
Imagine you need to inspect glass bottles on a production line. A single camera is not enough: depending on the viewing angle, certain defects are invisible due to material transparency, light reflections, or simply because they are hidden. The solution? Use multiple cameras placed at different angles to observe the same object.
生産ラインでガラス瓶を検査する必要があると想像してください。1台のカメラでは不十分です:視野角によっては、材料の透明性、光の反射、または単に隠れているために、特定の欠陥が見えません。解決策は?同じオブジェクトを観察するために、異なる角度に配置された複数のカメラを使用することです。
Mais comment combiner intelligemment les informations de toutes ces caméras ? C'est là qu'intervient Compact Mamba Multi-View (CMMV), une architecture que j'ai développée pour fusionner efficacement les vues multiples dans le contexte de l'inspection industrielle.
But how do you intelligently combine information from all these cameras? This is where Compact Mamba Multi-View (CMMV) comes in, an architecture I developed to efficiently fuse multiple views in the context of industrial inspection.
しかし、これらすべてのカメラからの情報をどのように賢く組み合わせるのでしょうか?ここでコンパクトMambaマルチビュー(CMMV)が登場します。これは、産業検査の文脈で複数のビューを効率的に融合するために開発したアーキテクチャです。
💡 Lien avec mes autres travaux : Cette méthode s'inscrit dans la continuité de mes recherches sur la fusion multi-vues. Alors qu'EDIF proposait une approche générique pour fusionner multi-modal ET multi-vues, CMMV se concentre sur l'efficacité et la compacité pour l'inspection industrielle mono-modale multi-vues.
💡 Connection with my other work: This method continues my research on multi-view fusion. While EDIF proposed a generic approach for fusing multi-modal AND multi-view, CMMV focuses on efficiency and compactness for mono-modal multi-view industrial inspection.
💡 他の研究との関連: この方法は、マルチビュー融合に関する私の研究の継続です。EDIFがマルチモーダルとマルチビューを融合する汎用的なアプローチを提案したのに対し、CMMVは単一モーダルマルチビュー産業検査の効率性とコンパクト性に焦点を当てています。
⚠️ Le problème : Pourquoi l'inspection multi-vues est difficile ?
⚠️ The Problem: Why is Multi-View Inspection Difficult?
⚠️ 問題:なぜマルチビュー検査は難しいのか?
L'inspection de matériaux transparents comme le verre présente trois défis majeurs :
Inspecting transparent materials like glass presents three major challenges:
ガラスのような透明な材料の検査には3つの主要な課題があります:
1️⃣ Effets optiques complexes
1️⃣ Complex Optical Effects
1️⃣ 複雑な光学効果
Les matériaux transparents créent des reflets, des réfractions, et des variations d'apparence selon l'angle de vue. Un défaut visible sous un angle peut être complètement invisible sous un autre.
Transparent materials create reflections, refractions, and appearance variations depending on the viewing angle. A defect visible from one angle may be completely invisible from another.
透明な材料は、視野角に応じて反射、屈折、および外観の変化を引き起こします。ある角度から見える欠陥は、別の角度からは完全に見えないことがあります。
2️⃣ Défauts subtils et localisés
2️⃣ Subtle and Localized Defects
2️⃣ 微妙で局所的な欠陥
Les marques d'effacement sur le verre sont souvent très petites et peu contrastées. De plus, leur sévérité doit être estimée sur une échelle ordinale (légère, modérée, sévère), ce qui complique encore la tâche.
Erasure marks on glass are often very small and low contrast. Moreover, their severity must be estimated on an ordinal scale (mild, moderate, severe), which further complicates the task.
ガラス上の摩耗マークは、しばしば非常に小さく、コントラストが低いです。さらに、その重症度は順序尺度(軽度、中程度、重度)で推定する必要があり、タスクをさらに複雑にします。
3️⃣ Bruit d'annotation
3️⃣ Annotation Noise
3️⃣ アノテーションノイズ
Lorsque plusieurs annotateurs humains évaluent la sévérité d'un défaut, ils ne sont pas toujours d'accord. Cette variabilité inter-annotateurs introduit du bruit dans les données d'entraînement, ce qui peut dégrader les performances du modèle.
When multiple human annotators evaluate the severity of a defect, they don't always agree. This inter-annotator variability introduces noise into the training data, which can degrade model performance.
複数の人間のアノテーターが欠陥の重症度を評価する場合、常に一致するわけではありません。このアノテーター間の変動性は、トレーニングデータにノイズを導入し、モデルのパフォーマンスを低下させる可能性があります。
🎯 Objectif : Concevoir une architecture capable d'exploiter les corrélations entre vues, de propager l'information contextuelle globale, et de régulariser les prédictions pour être robuste au bruit d'annotation.
🎯 Objective: Design an architecture capable of exploiting correlations between views, propagating global contextual information, and regularizing predictions to be robust to annotation noise.
🎯 目的: ビュー間の相関を活用し、グローバルなコンテキスト情報を伝播し、アノテーションノイズに対してロバストになるように予測を正則化できるアーキテクチャを設計すること。
🏗️ L'architecture Compact Mamba Multi-View (CMMV)
🏗️ The Compact Mamba Multi-View (CMMV) Architecture
🏗️ コンパクトMambaマルチビュー(CMMV)アーキテクチャ
L'architecture CMMV repose sur trois composants principaux qui travaillent ensemble pour fusionner efficacement les informations multi-vues :
The CMMV architecture relies on three main components that work together to efficiently fuse multi-view information:
CMMVアーキテクチャは、マルチビュー情報を効率的に融合するために連携する3つの主要コンポーネントに依存しています:
1️⃣ Encodeurs hiérarchiques à poids partagés
1️⃣ Shared-Weight Hierarchical Encoders
1️⃣ 共有重みの階層的エンコーダー
Chaque vue (image d'une caméra) est traitée par un encodeur convolutionnel qui extrait des caractéristiques à trois niveaux hiérarchiques :
Each view (camera image) is processed by a convolutional encoder that extracts features at three hierarchical levels:
各ビュー(カメラ画像)は、3つの階層レベルで特徴を抽出する畳み込みエンコーダーによって処理されます:
- Niveau 1 : Détails fins (textures, petits défauts)
- Niveau 2 : Caractéristiques intermédiaires (formes, contours)
- Niveau 3 : Représentations abstraites (contexte global)
- Level 1: Fine details (textures, small defects)
- Level 2: Intermediate features (shapes, contours)
- Level 3: Abstract representations (global context)
- レベル1:細かい詳細(テクスチャ、小さな欠陥)
- レベル2:中間特徴(形状、輪郭)
- レベル3:抽象的な表現(グローバルコンテキスト)
Point clé : Les poids de l'encodeur sont partagés entre toutes les vues. Cela signifie que le même réseau traite toutes les caméras, ce qui réduit considérablement le nombre de paramètres tout en garantissant une extraction cohérente des caractéristiques.
Key point: The encoder weights are shared across all views. This means the same network processes all cameras, which significantly reduces the number of parameters while ensuring consistent feature extraction.
重要なポイント: エンコーダーの重みはすべてのビュー間で共有されます。これは、同じネットワークがすべてのカメラを処理することを意味し、パラメータ数を大幅に削減しながら、一貫した特徴抽出を保証します。
2️⃣ Blocs Multi-View Mamba (MVMB)
2️⃣ Multi-View Mamba Blocks (MVMB)
2️⃣ マルチビューMambaブロック(MVMB)
C'est le cœur de l'innovation ! À chaque niveau hiérarchique, un bloc MVMB fusionne les caractéristiques de toutes les vues. Voici comment cela fonctionne :
This is the heart of the innovation! At each hierarchical level, an MVMB block fuses features from all views. Here's how it works:
これが革新の核心です!各階層レベルで、MVMBブロックがすべてのビューからの特徴を融合します。その仕組みは次のとおりです:
📌 Étape 1 : Projection en tokens
📌 Step 1: Projection into tokens
📌 ステップ1:トークンへの投影
Chaque carte de caractéristiques spatiale (image de features) est compressée en un token compact (vecteur de dimension d). Cela transforme les données 2D en une séquence 1D.
Each spatial feature map (feature image) is compressed into a compact token (vector of dimension d). This transforms 2D data into a 1D sequence.
各空間特徴マップ(特徴画像)は、コンパクトなトークン(次元dのベクトル)に圧縮されます。これにより、2Dデータが1Dシーケンスに変換されます。
📌 Étape 2 : Traitement par Mamba
📌 Step 2: Processing by Mamba
📌 ステップ2:Mambaによる処理
La séquence de tokens (une par vue) est traitée par un modèle d'espace d'états sélectif (Mamba). Mamba capture les dépendances entre vues de manière efficace grâce à sa complexité linéaire O(n) au lieu de O(n²) pour les Transformers.
The sequence of tokens (one per view) is processed by a selective state-space model (Mamba). Mamba captures dependencies between views efficiently thanks to its linear complexity O(n) instead of O(n²) for Transformers.
トークンのシーケンス(ビューごとに1つ)は、選択的状態空間モデル(Mamba)によって処理されます。MambaはTransformerのO(n²)ではなく、線形複雑度O(n)のおかげで、ビュー間の依存関係を効率的にキャプチャします。
📌 Étape 3 : Modulation FiLM
📌 Step 3: FiLM Modulation
📌 ステップ3:FiLM変調
Pour chaque vue, Mamba produit un token fusionné. Ce token est utilisé pour calculer des paramètres de modulation (γ, β) via FiLM (Feature-wise Linear Modulation). Ces paramètres sont appliqués aux caractéristiques originales de chaque vue : F̃ = γ ⊙ F + β. Cela permet à chaque vue de bénéficier du contexte multi-vues tout en conservant ses informations locales.
For each view, Mamba produces a fused token. This token is used to compute modulation parameters (γ, β) via FiLM (Feature-wise Linear Modulation). These parameters are applied to the original features of each view: F̃ = γ ⊙ F + β. This allows each view to benefit from multi-view context while retaining its local information.
各ビューについて、Mambaは融合されたトークンを生成します。このトークンは、FiLM(Feature-wise Linear Modulation)を介して変調パラメータ(γ、β)を計算するために使用されます。これらのパラメータは、各ビューの元の特徴に適用されます:F̃ = γ ⊙ F + β。これにより、各ビューはローカル情報を保持しながら、マルチビューコンテキストの恩恵を受けることができます。
3️⃣ Bloc de Fusion Global par Espace d'États (Global SSM)
3️⃣ Global State-Space Fusion Block (Global SSM)
3️⃣ グローバル状態空間融合ブロック(Global SSM)
Les blocs MVMB fusionnent les vues indépendamment à chaque échelle. Mais comment garantir une cohérence globale entre toutes les échelles et toutes les vues ? C'est le rôle du bloc Global SSM.
MVMB blocks fuse views independently at each scale. But how do we ensure global coherence across all scales and all views? This is the role of the Global SSM block.
MVMBブロックは、各スケールで独立してビューを融合します。しかし、すべてのスケールとすべてのビューにわたってグローバルな一貫性をどのように保証するのでしょうか?これがGlobal SSMブロックの役割です。
Tous les descripteurs fusionnés des trois niveaux hiérarchiques sont concaténés en une seule séquence, puis traités par un autre modèle Mamba. Cela permet de capturer les dépendances à longue portée entre vues et échelles, tout en restant computationnellement efficace.
All fused descriptors from the three hierarchical levels are concatenated into a single sequence, then processed by another Mamba model. This captures long-range dependencies between views and scales while remaining computationally efficient.
3つの階層レベルからのすべての融合記述子は、単一のシーケンスに連結され、別のMambaモデルによって処理されます。これにより、計算効率を維持しながら、ビューとスケール間の長距離依存関係をキャプチャします。
La représentation globale résultante H sert de mémoire partagée pour toutes les tâches en aval (détection, classification de sévérité, etc.).
The resulting global representation H serves as a shared memory for all downstream tasks (detection, severity classification, etc.).
結果として得られるグローバル表現Hは、すべての下流タスク(検出、重症度分類など)の共有メモリとして機能します。
4️⃣ Têtes de décodage par cross-attention
4️⃣ Cross-Attention Decoding Heads
4️⃣ クロスアテンションデコーディングヘッド
Chaque tâche (localisation par boîtes englobantes, classification de sévérité d'effacement) dispose de sa propre tête de décodage. Inspirées de l'architecture DETR, ces têtes utilisent un vecteur de requête appris qui interroge la représentation globale H via un mécanisme de cross-attention.
Each task (bounding box localization, erasure severity classification) has its own decoding head. Inspired by the DETR architecture, these heads use a learned query vector that queries the global representation H via a cross-attention mechanism.
各タスク(バウンディングボックスのローカリゼーション、摩耗重症度分類)には、独自のデコーディングヘッドがあります。DETRアーキテクチャに触発されたこれらのヘッドは、クロスアテンションメカニズムを介してグローバル表現Hをクエリする学習されたクエリベクトルを使用します。
Cela permet une spécialisation par tâche tout en partageant une représentation globale commune, ce qui améliore l'efficacité et la cohérence des prédictions.
This allows task specialization while sharing a common global representation, which improves prediction efficiency and consistency.
これにより、共通のグローバル表現を共有しながらタスクの専門化が可能になり、予測の効率性と一貫性が向上します。
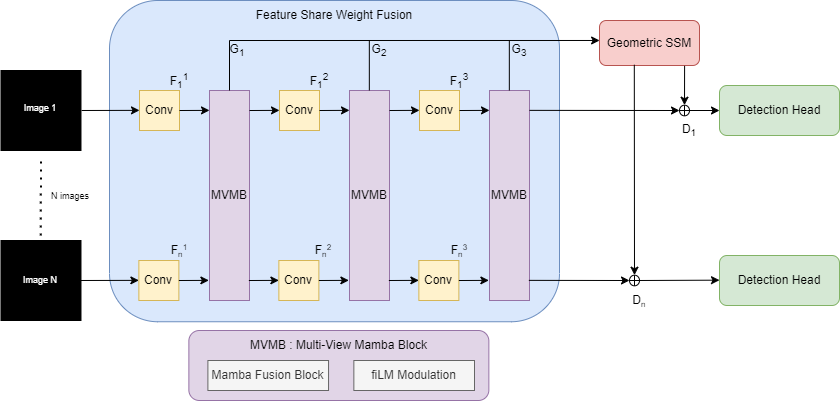
Figure : Distribution des niveaux de sévérité d'effacement dans le dataset MVEP. On observe une distribution déséquilibrée avec une prédominance des niveaux 1 et 2 (effacement léger à modéré), ce qui justifie l'utilisation d'une formulation ordinale pour la classification.
Figure: Distribution of erasure severity levels in the MVEP dataset. We observe an imbalanced distribution with a predominance of levels 1 and 2 (mild to moderate erasure), which justifies the use of an ordinal formulation for classification.
図: MVEPデータセットにおける摩耗重症度レベル(スカッフィング)の分布。レベル1と2(軽度から中程度の摩耗)が優勢な不均衡な分布が観察され、分類に順序定式化を使用することが正当化されます。
🎯 Classification ordinale de la sévérité d'effacement
🎯 Ordinal Classification of Erasure Severity
🎯 消去重症度の順序分類
Un aspect crucial de l'inspection industrielle est l'estimation de la sévérité de l'effacement. Contrairement à une classification classique où toutes les erreurs sont équivalentes, ici les classes sont ordonnées : confondre "effacement léger" et "effacement modéré" est moins grave que confondre "effacement léger" et "effacement sévère".
A crucial aspect of industrial inspection is estimating erasure severity. Unlike standard classification where all errors are equivalent, here classes are ordered: confusing "mild erasure" and "moderate erasure" is less serious than confusing "mild erasure" and "severe erasure".
産業検査の重要な側面は、摩耗重症度の推定です。すべてのエラーが同等である標準的な分類とは異なり、ここではクラスが順序付けられています:「軽度の摩耗」と「中程度の摩耗」を混同することは、「軽度の摩耗」と「重度の摩耗」を混同するよりも深刻ではありません。
Pour respecter cette structure ordinale, CMMV utilise une formulation par liens cumulatifs. Au lieu de prédire directement la classe, le modèle prédit K-1 seuils (pour K classes) et calcule la probabilité que la sévérité dépasse chaque seuil.
To respect this ordinal structure, CMMV uses a cumulative link formulation. Instead of directly predicting the class, the model predicts K-1 thresholds (for K classes) and calculates the probability that severity exceeds each threshold.
この順序構造を尊重するために、CMMVは累積リンク定式化を使用します。クラスを直接予測する代わりに、モデルはK-1のしきい値(Kクラスの場合)を予測し、重症度が各しきい値を超える確率を計算します。
💡 Avantage : Cette approche pénalise moins les erreurs entre classes adjacentes et améliore la robustesse face au bruit d'annotation, un problème fréquent en inspection industrielle où les annotateurs humains peuvent ne pas être d'accord sur la frontière exacte entre deux niveaux de sévérité.
💡 Advantage: This approach penalizes errors between adjacent classes less and improves robustness to annotation noise, a common problem in industrial inspection where human annotators may disagree on the exact boundary between two severity levels.
💡 利点: このアプローチは、隣接するクラス間のエラーをより少なくペナルティ化し、アノテーションノイズに対するロバスト性を向上させます。これは、人間のアノテーターが2つの重症度レベル間の正確な境界について意見が一致しない可能性がある産業検査でよくある問題です。
⚙️ Entraînement multi-tâches avec régularisation multi-vues
⚙️ Multi-Task Training with Multi-View Regularization
⚙️ マルチビュー正則化によるマルチタスクトレーニング
L'entraînement de CMMV combine cinq fonctions de perte complémentaires pour garantir des prédictions robustes et cohérentes :
CMMV training combines five complementary loss functions to ensure robust and consistent predictions:
CMMVのトレーニングは、ロバストで一貫した予測を保証するために5つの補完的な損失関数を組み合わせます:
1️⃣ Perte ordinale (Ordinal Cross-Entropy)
1️⃣ Ordinal Loss (Ordinal Cross-Entropy)
1️⃣ 順序損失(順序クロスエントロピー)
Pénalise les erreurs de classification de sévérité en respectant l'ordre naturel des classes.
Penalizes severity classification errors while respecting the natural order of classes.
クラスの自然な順序を尊重しながら、重症度分類エラーをペナルティ化します。
2️⃣ Perte de régression géométrique (Smooth-ℓ1)
2️⃣ Geometric Regression Loss (Smooth-ℓ1)
2️⃣ 幾何学的回帰損失(Smooth-ℓ1)
Optimise la localisation des boîtes englobantes pour chaque vue valide.
Optimizes bounding box localization for each valid view.
各有効なビューのバウンディングボックスのローカリゼーションを最適化します。
3️⃣ Perte de cohérence de classe (KL Divergence)
3️⃣ Class Consistency Loss (KL Divergence)
3️⃣ クラス一貫性損失(KLダイバージェンス)
Force les prédictions de toutes les vues à être cohérentes entre elles. Chaque vue doit prédire une distribution de classes proche de la moyenne multi-vues. Cela réduit les incohérences causées par le bruit d'annotation.
Forces predictions from all views to be consistent with each other. Each view must predict a class distribution close to the multi-view average. This reduces inconsistencies caused by annotation noise.
すべてのビューからの予測が互いに一貫していることを強制します。各ビューは、マルチビュー平均に近いクラス分布を予測する必要があります。これにより、アノテーションノイズによる不一致が減少します。
4️⃣ Perte d'alignement des embeddings (Cosine Similarity)
4️⃣ Embedding Alignment Loss (Cosine Similarity)
4️⃣ 埋め込みアライメント損失(コサイン類似度)
Encourage les représentations latentes de toutes les vues à être similaires (invariance au point de vue). Cela stabilise l'apprentissage et améliore la généralisation.
Encourages latent representations from all views to be similar (viewpoint invariance). This stabilizes learning and improves generalization.
すべてのビューからの潜在表現が類似していることを奨励します(視点不変性)。これにより、学習が安定し、汎化が向上します。
5️⃣ Perte de lissage séquentiel (Sequential Smoothness)
5️⃣ Sequential Smoothness Loss
5️⃣ シーケンシャル平滑化損失
Pénalise les variations brusques entre vues adjacentes dans la séquence ordonnée de caméras. Cela exploite la géométrie physique du système multi-caméras et améliore la robustesse aux vues bruitées.
Penalizes abrupt variations between adjacent views in the ordered camera sequence. This exploits the physical geometry of the multi-camera system and improves robustness to noisy views.
順序付けられたカメラシーケンス内の隣接するビュー間の急激な変動をペナルティ化します。これにより、マルチカメラシステムの物理的な幾何学が活用され、ノイズの多いビューに対するロバスト性が向上します。
🎯 Résultat : Cette combinaison de pertes crée un système robuste qui exploite pleinement les corrélations multi-vues tout en étant résistant au bruit d'annotation et aux vues ambiguës.
🎯 Result: This combination of losses creates a robust system that fully exploits multi-view correlations while being resistant to annotation noise and ambiguous views.
🎯 結果: この損失の組み合わせにより、アノテーションノイズや曖昧なビューに対して耐性がありながら、マルチビュー相関を完全に活用するロバストなシステムが作成されます。
🛢️ Le dataset MVEP : Multi-View Emballage Packaging
🛢️ The MVEP Dataset: Multi-View Emballage Packaging
🛢️ MVEPデータセット:マルチビュー包装パッケージング
Pour évaluer CMMV, nous avons créé le dataset MVEP, un dataset d'inspection de bouteilles en verre capturées sous plusieurs angles. Ce dataset présente des caractéristiques uniques qui en font un benchmark difficile pour la fusion multi-vues :
To evaluate CMMV, we created the MVEP dataset, a dataset of glass bottle inspection captured from multiple angles. This dataset has unique characteristics that make it a challenging benchmark for multi-view fusion:
CMMVを評価するために、複数の角度から撮影されたガラス瓶検査のMVEPデータセットを作成しました。このデータセットには、マルチビュー融合にとって困難なベンチマークとなるユニークな特性があります:
- Matériau transparent : Le verre crée des effets optiques complexes (reflets, réfractions)
- Défauts subtils : Les marques d'effacement sont petites et peu contrastées
- Annotations ordinales : La sévérité est évaluée sur une échelle de 1 à 4
- Vues synchronisées : Plusieurs caméras observent le même objet simultanément
- Variabilité d'annotation : Présence de bruit dû aux désaccords entre annotateurs
- Transparent material: Glass creates complex optical effects (reflections, refractions)
- Subtle defects: Erasure marks are small and low contrast
- Ordinal annotations: Severity is evaluated on a scale from 1 to 4
- Synchronized views: Multiple cameras observe the same object simultaneously
- Annotation variability: Presence of noise due to disagreements between annotators
- 透明な材料:ガラスは複雑な光学効果(反射、屈折)を生み出します
- 微妙な欠陥:摩耗マークは小さく、コントラストが低い
- 順序アノテーション:重症度は1から4のスケールで評価されます
- 同期ビュー:複数のカメラが同じオブジェクトを同時に観察します
- アノテーションの変動性:アノテーター間の不一致によるノイズの存在
📊 En savoir plus sur MVEP : Pour des statistiques détaillées, des exemples visuels et des informations sur l'accès au dataset, consultez la page dédiée au dataset MVEP.
📊 Learn more about MVEP: For detailed statistics, visual examples, and information on dataset access, visit the dedicated MVEP dataset page.
📊 MVEPの詳細: 詳細な統計、視覚的な例、データセットへのアクセスに関する情報については、専用のMVEPデータセットページをご覧ください。
📊 Résultats expérimentaux
📊 Experimental Results
📊 実験結果
Les expériences sur le dataset MVEP démontrent l'efficacité de CMMV. Deux comparaisons principales ont été réalisées :
Experiments on the MVEP dataset demonstrate the effectiveness of CMMV. Two main comparisons were performed:
MVEPデータセットでの実験は、CMMVの有効性を実証しています。2つの主要な比較が行われました:
1️⃣ Mamba vs Transformer
1️⃣ Mamba vs Transformer
1️⃣ Mamba vs Transformer
Comparaison entre l'architecture Mamba (CMMV) et une variante utilisant des Transformers, en deux configurations : Small (modèle compact) et Large (modèle plus expressif).
Comparison between the Mamba architecture (CMMV) and a variant using Transformers, in two configurations: Small (compact model) and Large (more expressive model).
Mambaアーキテクチャ(CMMV)とTransformerを使用したバリアントの比較、2つの構成で:Small(コンパクトモデル)とLarge(より表現力のあるモデル)。
| Modèle |
Paramètres |
F1-Score (%) |
Accuracy (%) |
Model |
Parameters |
F1-Score (%) |
Accuracy (%) |
モデル |
パラメータ |
F1スコア (%) |
精度 (%) |
| CMMV-Small |
8.2M |
82.4 |
79.1 |
| Transformer-Small |
8.5M |
80.7 |
77.3 |
| CMMV-Large |
14.1M |
84.9 |
81.6 |
| Transformer-Large |
15.3M |
83.1 |
79.8 |
Observation : CMMV surpasse systématiquement les Transformers en F1-Score et Accuracy, tout en utilisant moins de paramètres. Cela confirme l'efficacité de l'architecture Mamba pour la fusion multi-vues.
Observation: CMMV consistently outperforms Transformers in F1-Score and Accuracy while using fewer parameters. This confirms the effectiveness of the Mamba architecture for multi-view fusion.
観察: CMMVは、より少ないパラメータを使用しながら、F1スコアと精度でTransformerを一貫して上回ります。これは、マルチビュー融合におけるMambaアーキテクチャの有効性を確認しています。
2️⃣ Comparaison avec les baselines
2️⃣ Comparison with Baselines
2️⃣ ベースラインとの比較
Comparaison avec des approches mono-vue (DETR) et multi-vues (DETR avec fusion par vote majoritaire ou soft voting, et EDIF).
Comparison with single-view approaches (DETR) and multi-view approaches (DETR with majority or soft voting fusion, and EDIF).
単一ビューアプローチ(DETR)およびマルチビューアプローチ(多数決またはソフト投票融合を使用したDETR、およびEDIF)との比較。
| Méthode |
mAP (%) |
F1-Score (%) |
Accuracy (%) |
Method |
mAP (%) |
F1-Score (%) |
Accuracy (%) |
手法 |
mAP (%) |
F1スコア (%) |
精度 (%) |
| DETR mono-vue |
71.3 |
74.2 |
70.5 |
| DETR multi-vue (majority) |
73.8 |
76.9 |
73.1 |
| DETR multi-vue (soft) |
75.1 |
78.3 |
74.8 |
| EDIF |
78.6 |
80.1 |
77.2 |
| CMMV (ours) |
77.2 |
84.9 |
81.6 |
Analyse : CMMV obtient le meilleur F1-Score et la meilleure Accuracy, ce qui est crucial pour l'inspection industrielle où la classification correcte de la sévérité est prioritaire. Bien que le mAP soit légèrement inférieur à EDIF, CMMV excelle dans la tâche de classification ordinale grâce à sa formulation spécialisée et ses pertes de régularisation multi-vues.
Analysis: CMMV achieves the best F1-Score and Accuracy, which is crucial for industrial inspection where correct severity classification is a priority. Although mAP is slightly lower than EDIF, CMMV excels in the ordinal classification task thanks to its specialized formulation and multi-view regularization losses.
分析: CMMVは最高のF1スコアと精度を達成しており、これは重症度の正しい分類が優先される産業検査にとって重要です。mAPはEDIFよりわずかに低いものの、CMMVは専門的な定式化とマルチビュー正則化損失により、順序分類タスクで優れています。
🔮 Limitations et perspectives futures
🔮 Limitations and Future Perspectives
🔮 制限と将来の展望
Bien que CMMV démontre d'excellentes performances, plusieurs pistes d'amélioration restent à explorer :
Although CMMV demonstrates excellent performance, several avenues for improvement remain to be explored:
CMMVは優れたパフォーマンスを示していますが、いくつかの改善の余地が残されています:
- Variantes Mamba orientées vision : Développer des mécanismes de balayage spatialement conscients, une propagation d'état bidirectionnelle, ou un filtrage sélectif multi-échelle pour mieux exploiter la structure 2D des images
- Matching inter-vues explicite : Intégrer des approches basées sur des graphes (comme dans EDIF) pour améliorer l'appariement d'objets entre vues
- Robustesse accrue : Évaluer les performances sous bruit d'annotation plus élevé, disponibilité partielle des vues, et domaines d'application plus diversifiés (perception robotique, systèmes multi-caméras à grande échelle)
- Vision-oriented Mamba variants: Develop spatially aware scanning mechanisms, bidirectional state propagation, or multi-scale selective filtering to better exploit the 2D structure of images
- Explicit inter-view matching: Integrate graph-based approaches (as in EDIF) to improve object matching between views
- Increased robustness: Evaluate performance under higher annotation noise, partial view availability, and more diverse application domains (robotic perception, large-scale multi-camera systems)
- ビジョン指向のMambaバリアント:画像の2D構造をより活用するために、空間認識スキャンメカニズム、双方向状態伝播、またはマルチスケール選択フィルタリングを開発
- 明示的なビュー間マッチング:ビュー間のオブジェクトマッチングを改善するために、グラフベースのアプローチ(EDIFのように)を統合
- ロバスト性の向上:より高いアノテーションノイズ、部分的なビューの可用性、およびより多様なアプリケーションドメイン(ロボット知覚、大規模マルチカメラシステム)でのパフォーマンスを評価
🎓 Conclusion
🎓 Conclusion
🎓 結論
Compact Mamba Multi-View démontre qu'il est possible de créer des systèmes d'inspection industrielle multi-vues à la fois compacts, efficaces et robustes. En combinant l'architecture Mamba avec une formulation ordinale et des pertes de régularisation multi-vues, CMMV atteint des performances de pointe en classification de sévérité tout en utilisant significativement moins de paramètres que les approches basées sur les Transformers.
Compact Mamba Multi-View demonstrates that it is possible to create multi-view industrial inspection systems that are simultaneously compact, efficient, and robust. By combining the Mamba architecture with an ordinal formulation and multi-view regularization losses, CMMV achieves state-of-the-art performance in severity classification while using significantly fewer parameters than Transformer-based approaches.
Compact Mamba Multi-Viewは、コンパクトで効率的かつロバストなマルチビュー産業検査システムを作成できることを実証しています。Mambaアーキテクチャを順序定式化とマルチビュー正則化損失と組み合わせることで、CMMVはTransformerベースのアプローチよりも大幅に少ないパラメータを使用しながら、重症度分類で最先端のパフォーマンスを達成しています。
Cette approche ouvre la voie à des applications embarquées et temps réel de l'inspection multi-vues, particulièrement adaptées aux contraintes industrielles où la compacité, la rapidité et la fiabilité sont essentielles.
This approach paves the way for embedded and real-time multi-view inspection applications, particularly suited to industrial constraints where compactness, speed, and reliability are essential.
このアプローチは、コンパクト性、速度、信頼性が不可欠な産業的制約に特に適した、組み込みおよびリアルタイムのマルチビュー検査アプリケーションへの道を開きます。
📚 Quelques références scientifiques
📚 Key Scientific References
📚 主要な科学的参考文献
-
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Gu & Dao (2023) - 🔗 arXiv:2312.00752
-
End-to-End Object Detection with Transformers (DETR)
Carion et al. (ECCV 2020) - 🔗 arXiv:2005.12872
-
FiLM: Visual Reasoning with a General Conditioning Layer
Perez et al. (AAAI 2018) - 🔗 arXiv:1709.07871
-
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Gu & Dao (2023) - 🔗 arXiv:2312.00752
-
End-to-End Object Detection with Transformers (DETR)
Carion et al. (ECCV 2020) - 🔗 arXiv:2005.12872
-
FiLM: Visual Reasoning with a General Conditioning Layer
Perez et al. (AAAI 2018) - 🔗 arXiv:1709.07871
-
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Gu & Dao (2023) - 🔗 arXiv:2312.00752
-
End-to-End Object Detection with Transformers (DETR)
Carion et al. (ECCV 2020) - 🔗 arXiv:2005.12872
-
FiLM: Visual Reasoning with a General Conditioning Layer
Perez et al. (AAAI 2018) - 🔗 arXiv:1709.07871
📚 Pour aller plus loin
📚 Further Reading
📚 さらに詳しく
📝 Articles connexes
📝 Related Articles
📝 関連記事