MVEP - Multi-View Partial Erasure Pattern Dataset
Dataset dédié à l'inspection automatisée de conteneurs en verre avec annotations multi-vues
🖼️ Aperçu du Dataset

Illustration des composants du dataset : différents patterns visuels appliqués sur les conteneurs, points de vue des caméras, positions des conteneurs (Bottom, Middle, Top), et exemples représentatifs des cinq classes d'effacement.
📖 Introduction
Le développement de méthodes robustes d'inspection nécessite des datasets qui reflètent fidèlement les contraintes rencontrées dans les environnements industriels réels. Dans le contexte de l'inspection de conteneurs en verre, les datasets publiquement disponibles restent rares et mal adaptés aux défis spécifiques de l'analyse de dégradation de surface sur des matériaux transparents.
Dans les environnements industriels, les acquisitions d'images impliquent souvent des conteneurs de marque portant des logos, des blasons en relief ou des éléments visuels propriétaires. Par conséquent, les datasets collectés à partir de lignes de production réelles ne peuvent pas être rendus publics en raison de contraintes de confidentialité et de propriété intellectuelle.
Pour répondre à cette limitation, nous introduisons le Multi-View Partial Erasure Pattern on Transparent Container Dataset, un dataset publiquement partageable conçu pour reproduire les principaux défis visuels et géométriques de l'inspection industrielle des rayures tout en évitant le contenu sensible. Le dataset est composé de conteneurs en verre sans logos ni marquage, sur lesquels des patterns d'effacement synthétiques sont appliqués. Ces patterns émulent les marques d'effacement observées dans les usines réelles, avec des formes, des emplacements spatiaux et des degrés d'effacement variés.
Bien que la diversité des formes de conteneurs et des éléments décoratifs soit intentionnellement réduite par rapport aux données du monde réel, les contraintes de détection et de classification restent proches des conditions industrielles, notamment grâce à l'utilisation d'étiquettes ordinales de sévérité d'usure.
🔬 Setup d'Acquisition Multi-Vue
Le setup d'acquisition multi-vue est inspiré des systèmes d'inspection industriels basés sur convoyeur et est conçu pour fournir une couverture visuelle complète de la surface du conteneur. Le dataset repose sur douze caméras synchronisées disposées autour de l'axe du convoyeur, chacune capturant le même conteneur en verre depuis une direction de vue distincte.
Cette configuration permet l'observation des dégradations de surface sous différentes orientations, ce qui est essentiel compte tenu de la nature partiellement transparente et réfléchissante du verre.
🎥 Configuration des Caméras
Les caméras sont distribuées sur deux stations d'acquisition symétriques, chacune comprenant trois axes optiques. La deuxième station est obtenue en appliquant une symétrie horizontale à la première par rapport à l'axe du convoyeur.
Au sein de chaque station, les axes optiques sont séparés par un espacement angulaire de 50°, ce qui correspond à une configuration industrielle couramment utilisée. Dans cette configuration, les caméras sont orientées à environ 40° par rapport à l'axe du convoyeur, offrant un compromis favorable entre la couverture de surface, la visibilité des défauts et la stabilité de l'éclairage.
📐 Vues Frontales et Vues Élevées
Pour chaque axe optique, deux points de vue de caméra sont définis : une vue frontale et une vue élevée.
Caméras à vue frontale : Positionnées le long d'un axe optique horizontal à faible angle, capturant des images aussi proches que possible du plan du convoyeur tout en garantissant que le convoyeur lui-même reste en dehors du champ de vision.
Caméras à vue élevée : Partagent la même orientation d'axe optique mais sont décalées verticalement et montées à une position plus élevée. Dans le setup proposé, les caméras à vue élevée sont placées 83 mm au-dessus des caméras à vue frontale correspondantes et sont inclinées vers le bas de -30°, correspondant à la configuration utilisée pour les petits articles.
Ce point de vue élevé et incliné permet une observation partielle en plongée du conteneur, ce qui améliore considérablement la visibilité des effacements de surface dans des régions spécifiques. La combinaison de vues frontales et de vues élevées permet de capturer des informations visuelles complémentaires.
Note : Les vues frontales fournissent une couverture complète de la surface du conteneur mais sont affectées par la superposition de patterns due à la transparence du verre, tandis que les vues élevées réduisent les effets de superposition et améliorent la visibilité des effacements dans les régions supérieures du conteneur.
🏗️ Construction du Dataset
Le dataset a été conçu pour évaluer systématiquement la robustesse des modèles de détection d'effacement dans des conditions visuelles contrôlées mais réalistes. Sa construction repose sur la combinaison de multiples patterns visuels, points de vue de caméra, placements de conteneurs et niveaux de dégradation.
Le dataset contient 16,452 images, organisées en scènes multi-vues synchronisées. Chaque scène correspond à un seul conteneur en verre observé depuis 12 points de vue, fournissant plusieurs perspectives visuelles du même objet physique.
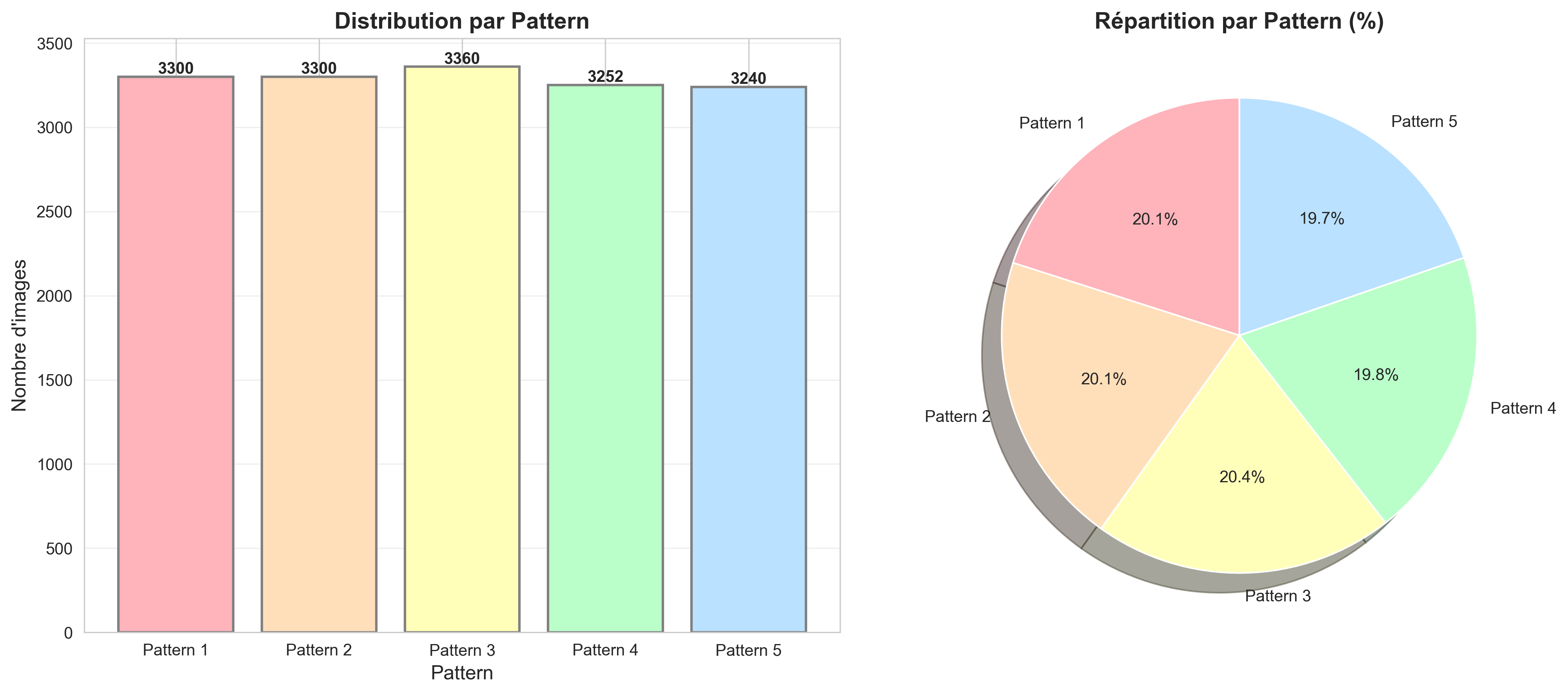
🎨 Patterns Visuels
Cinq patterns distincts ont été considérés pour générer le contenu visuel sur les parois des conteneurs. Les patterns appliqués appartiennent à cinq familles de patterns distinctes et peuvent apparaître à différentes positions sur la surface du conteneur.
Patterns 1 et 3 : Présentent des structures verticalement discontinues et ont été spécifiquement introduits pour défier la capacité du modèle à détecter les effacements verticaux, qui partagent la même orientation dominante.
Patterns 2 et 3 : Incluent des discontinuités horizontales, introduisant des variations structurelles complémentaires.
Pattern 4 : Correspond à une disposition en grille régulière, qui fournit de forts indices géométriques et facilite l'identification des effacements en offrant une référence visuelle claire.
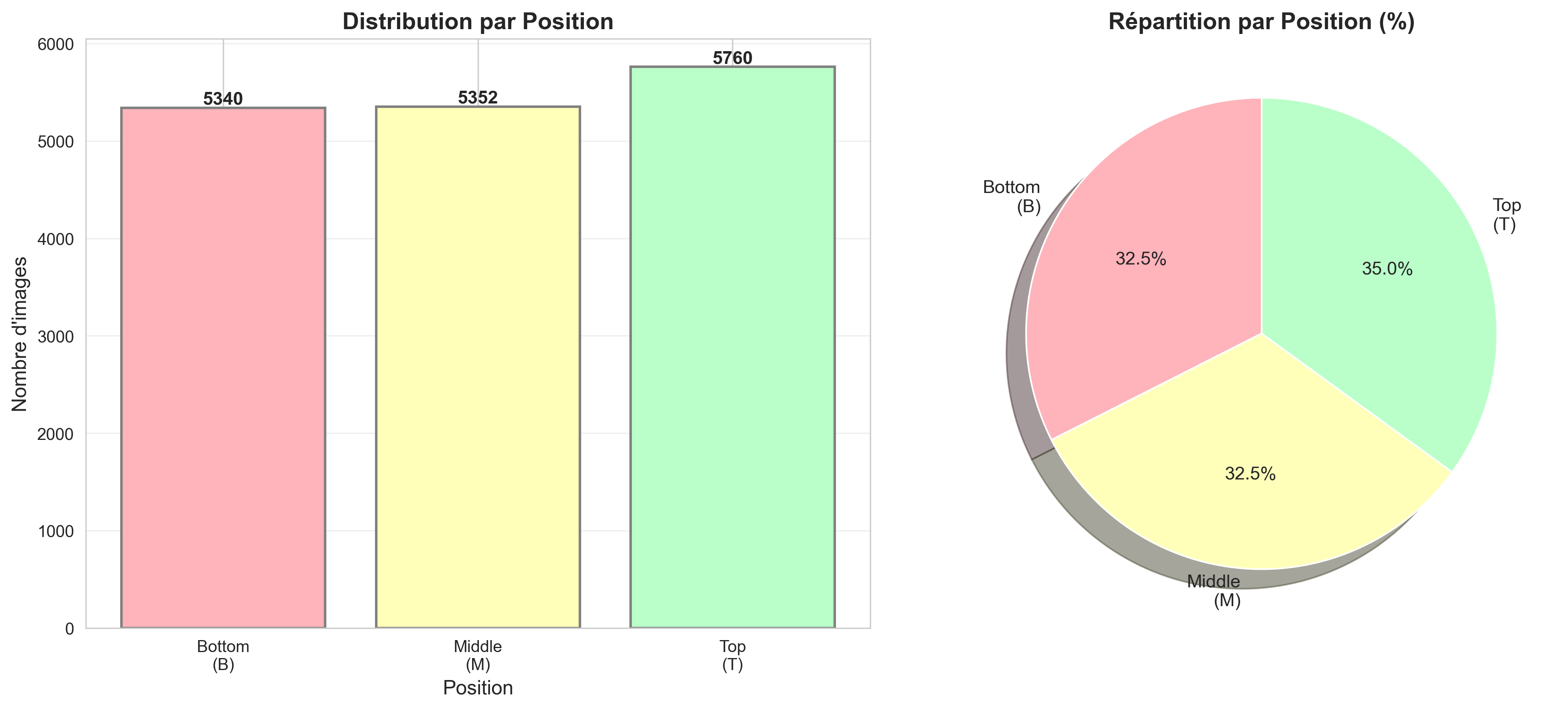
📐 Positions des Conteneurs
Les placements Bottom, Middle et Top des conteneurs ont été introduits pour exploiter ces conditions de visibilité dépendantes du point de vue. Chaque configuration de conteneur a été capturée en utilisant douze vues de caméra distinctes.
Les six premières vues correspondent à des acquisitions frontales, permettant d'observer le contour complet de la paroi du conteneur.
Les six vues restantes ont été générées à partir de positions de caméra élevées avec un angle incliné, fournissant des perspectives partielles en plongée. Ces points de vue complémentaires sont essentiels pour relever les défis induits par la transparence du verre.
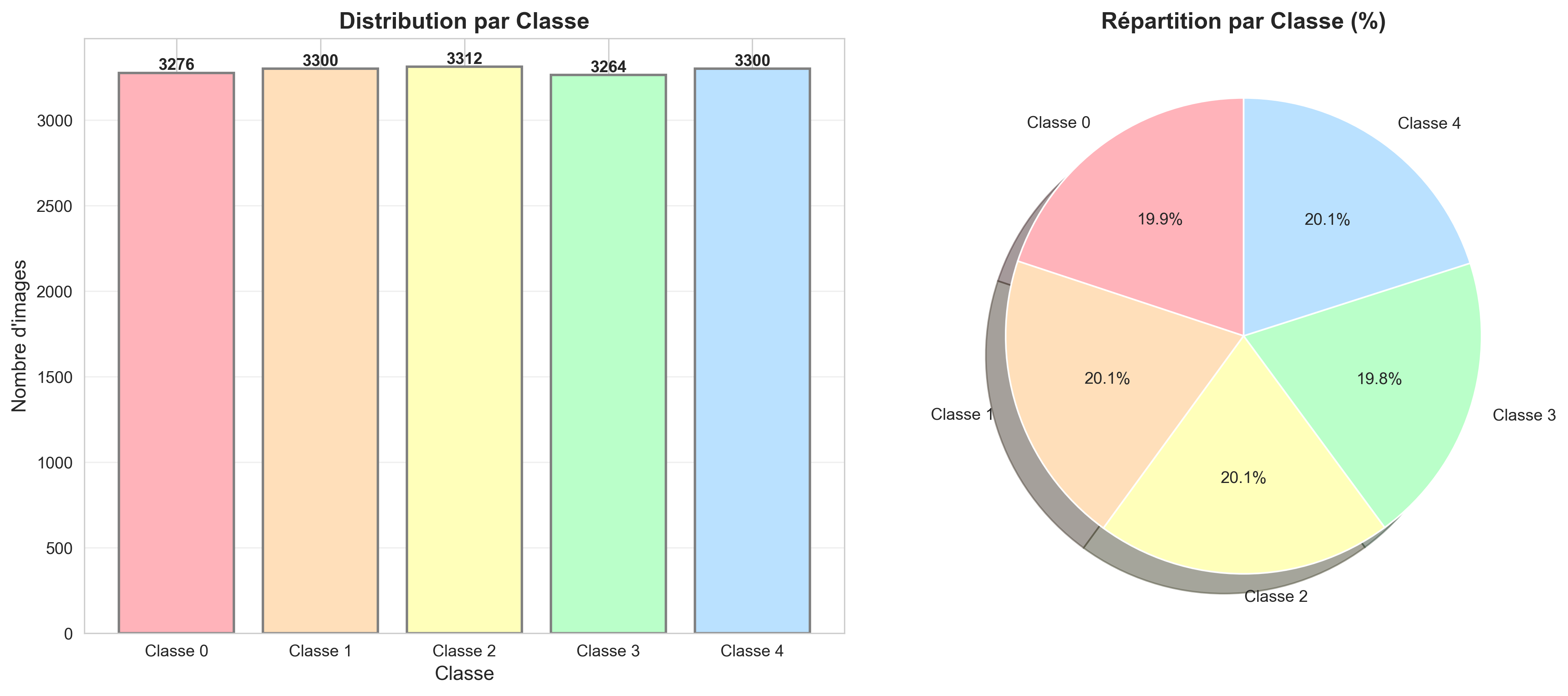
🏷️ Classes et Annotations
Le dataset est annoté en utilisant cinq classes discrètes, étiquetées de 0 à 4, selon le nombre d'effacements présents sur la paroi du conteneur. Pour chaque pattern, plusieurs niveaux de dégradation sont définis pour simuler l'usure progressive.
Il est important de noter que l'effacement partiel n'est pas nécessairement visible depuis tous les points de vue et peut être difficile à détecter dans certaines orientations en raison de la transparence, de la réfraction et des effets spéculaires. Cette caractéristique reflète fidèlement les scénarios d'inspection réels, où les défauts de surface ne peuvent être observables que sous des angles spécifiques.
Absence d'effacement
Un effacement
Deux ou trois effacements
Quatre ou cinq effacements
Six effacements
Note importante : Pour augmenter le niveau de difficulté et mieux refléter les scénarios industriels réels, les Classes 2 et 3 incluent intentionnellement une plage plus large de nombres d'effacements, résultant en une variabilité intra-classe. Ce choix de conception empêche des frontières de classe trop nettes et encourage le modèle à apprendre des critères de décision plus robustes.
🏷️ Processus d'Étiquetage
Le processus d'étiquetage implique deux aspects complémentaires : l'attribution de classe et l'annotation de bounding box.
Attribution de classe : Les informations de classe ont été générées et stockées simultanément avec l'acquisition d'images, garantissant que chaque image était associée à une étiquette de classe avant l'étape d'annotation. Par conséquent, l'étiquetage de classe ne repose pas sur une intervention manuelle a posteriori et reste cohérent sur l'ensemble du dataset.
Annotation de bounding box : Une stratégie d'étiquetage semi-automatique a été adoptée. Initialement, 450 images ont été annotées manuellement avec des bounding boxes, avec un soin particulier pour assurer une grande diversité en termes de classes, positions de conteneurs, patterns visuels et points de vue de caméra.
L'ensemble annoté a ensuite été utilisé pour entraîner un modèle YOLOv8 chargé exclusivement d'apprendre à localiser avec précision les effacements via la prédiction de bounding box. Une fois entraîné, le modèle a été utilisé pour inférer des bounding boxes sur l'ensemble du dataset. Ce processus itératif d'inférence, de révision et de réentraînement a été répété jusqu'à ce qu'aucune erreur d'annotation significative ne soit observée.
📊 Statistiques du Dataset
📈 Distribution des Données
Distribution par Pattern
Distribution par Position
Distribution par Classe
📝 Citation
Si vous utilisez ce dataset dans vos travaux de recherche, veuillez citer la publication suivante :
@misc{bernardi2026compact,
title={Compact Mamba Multi-View for Object Detection},
author={Bernardi, Gwendal and Brisebarre, Godefroy and Roman, Sebastien and Ardabilian, Mohsen and Dellandrea, Emmanuel},
year={2026},
note={hal-05494004}
}
⚖️ Licence
Ce dataset est mis à disposition sous licence Creative Commons Attribution 4.0 International (CC BY 4.0). Vous êtes libre de partager et adapter le dataset pour tout usage, y compris commercial, à condition de créditer les auteurs.